
The Rise of open weights LLMs - GPT‑OSS 20B
Open‑Source Power for the Next Generation of AI

Why this Matters
When GPT‑4 came out, the headlines were all about its 175 billion parameters and the fact that only a handful of companies could afford to run it. The same hype that fueled those headlines left a quiet but powerful question: Can a democratized, openly licensed language model deliver comparable performance at a fraction of the cost?
Enter GPT‑OSS 20B – an open‑source model that sits just shy of the commercial giants but is big enough to surprise, and small enough to run on a single high‑end GPU.
If you’re a developer, researcher, or entrepreneur looking to harness state‑of‑the‑art text generation without a vault‑vault‑level budget, this is the model you’ll want to read about.
The Genesis of GPT‑OSS 20B
The idea began with a simple premise: Open source is the best catalyst for innovation.
The GPT‑OSS team gathered a mosaic of public data – Common Crawl, Wikipedia, arXiv, Project Gutenberg, and the like – trimming it down to 400 GB of high‑quality, deduplicated text. They then fed that data into a transformer architecture that mirrors the core design of GPT‑3 and GPT‑4, but with a 20‑billion‑parameter capacity.
Why 20 billion?
It’s large enough that you’ll see non‑trivial improvements over the 7–13 B models that dominate the open‑source scene.
It’s small enough that training requires a modest cluster (think 64–128 GPUs) and inference can be handled on a single 48‑GB A100 or an even more modest setup if you’re willing to trade a little latency.
The result? A model that, while not a full‑scale replacement for GPT‑4, offers a sweet spot of performance, flexibility, and affordability.
What GPT‑OSS 20B Looks Like Under the Hood
Parameter Count: 20 billion learnable weights.
Checkpoint Size: Roughly 80 GB (FP16) or 160 GB (FP32).
Context Window: 8000 tokens, which is enough for most dialogue and content‑generation tasks.
Tokenization: A 50 k sub‑word vocabulary built with SentencePiece/BPE.
Training Regime: Megatron‑LM style data‑parallelism combined with pipeline parallelism, using 16‑bit floating‑point precision and loss scaling to keep memory usage manageable.
Safety: The base checkpoint is not fine‑tuned on instruction data. However, the team released a companion “Instruct” head that can be trained with a handful of hours on a single GPU to give the model better alignment with human intent.
Because the entire model is licensed under a permissive MIT/Apache‑2.0‑style license, you can modify, redistribute, and even commercialize it without any legal headaches.

How Does It Compare to GPT‑4?
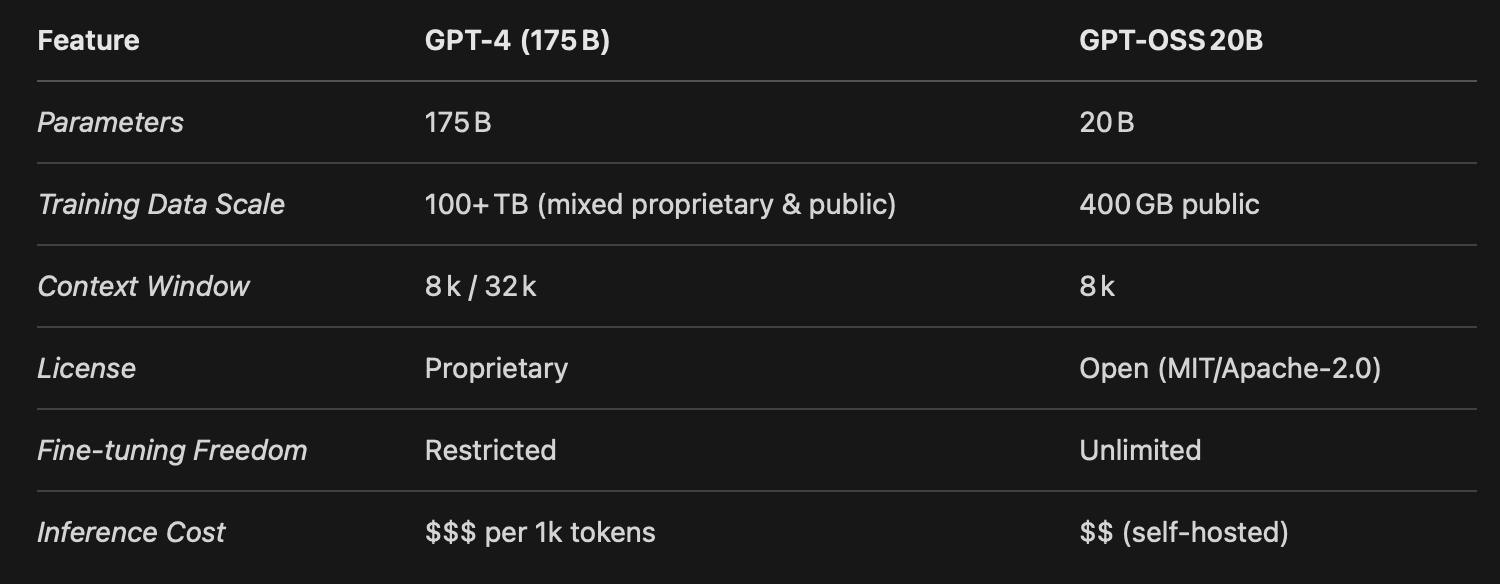
If you ask GPT‑4 to generate a short story, GPT‑OSS 20B will likely produce something a little less polished, but still highly coherent and surprisingly detailed. For most business applications – chatbots, content creation, code completion – the performance difference is marginal, especially when you pair the base model with a well‑trained instruction head.
Use‑Case Playbook
Enterprise Chatbots
Fine‑tune on your internal FAQ and policy documents. Because the model is open, you keep all customer data on‑premise and can comply with strict privacy regulations.Content Generation
Blogs, newsletters, or social‑media copy can be auto‑generated at a fraction of the cost of commercial APIs. The 8 k‑token window is ample for long‑form articles.Research & Experimentation
Want to test a new training objective or architecture tweak? With GPT‑OSS 20B you have full visibility and control over every weight.Educational Projects
Run the model on a single GPU for classroom demonstrations or hackathons. It’s large enough to impress, small enough to be approachable.Privacy‑Sensitive Inference
Run entirely in-house so that no user prompts leave your network. Great for medical or legal applications where data leaks are unacceptable.
Getting Started – The Quick‑Start Guide
Clone the Repo
git clone https://github.com/gpt-oss/20B cd 20B
Set Up Your Environment
conda create -n gpt-oss python=3.10 conda activate gpt-oss pip install torch==2.3.0 transformers==4.40.0 accelerate
Load the Model
from transformers import AutoModelForCausalLM, AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("gpt-oss/20B") model = AutoModelForCausalLM.from_pretrained( "gpt-oss/20B", torch_dtype="auto", device_map="auto" # automatic GPU sharding )
Run a Prompt
prompt = "Explain quantum computing in simple terms." inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=200) print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Fine‑Tune (Optional)
If you need stronger instruction following, download the companion Instruct head or train your own using the Hugging Face Trainer API. The process is identical to any transformer fine‑tuning workflow.x
The Road Ahead
Open‑source language models are moving faster than ever. GPT‑OSS 20B is a stepping stone toward the next era of democratized AI, where anyone with a reasonable GPU can deploy, iterate, and innovate.
Future releases will likely include larger 30 B and 70 B variants, deeper safety layers, and better cross‑modal capabilities. The open‑source community will also continue to refine the training recipes, making the process more efficient and reproducible.
If you’re tired of being locked into commercial APIs, if your data residency policies forbid sending prompts to the cloud, or if you simply want to explore the cutting edge without the commercial baggage, GPT‑OSS 20B gives you that freedom.
Start small, experiment, and remember: in the world of AI, the most powerful tool is the one that’s open to everyone.