


The Rise of Llama 3.1
A New Contender in Open Source AI Language Models almost on par with Closed Source

The artificial intelligence landscape has recently witnessed a significant development with the introduction of Llama 3.1, Meta's latest large language model. This new entrant has quickly garnered attention in the AI community due to its impressive performance across a wide range of benchmarks.

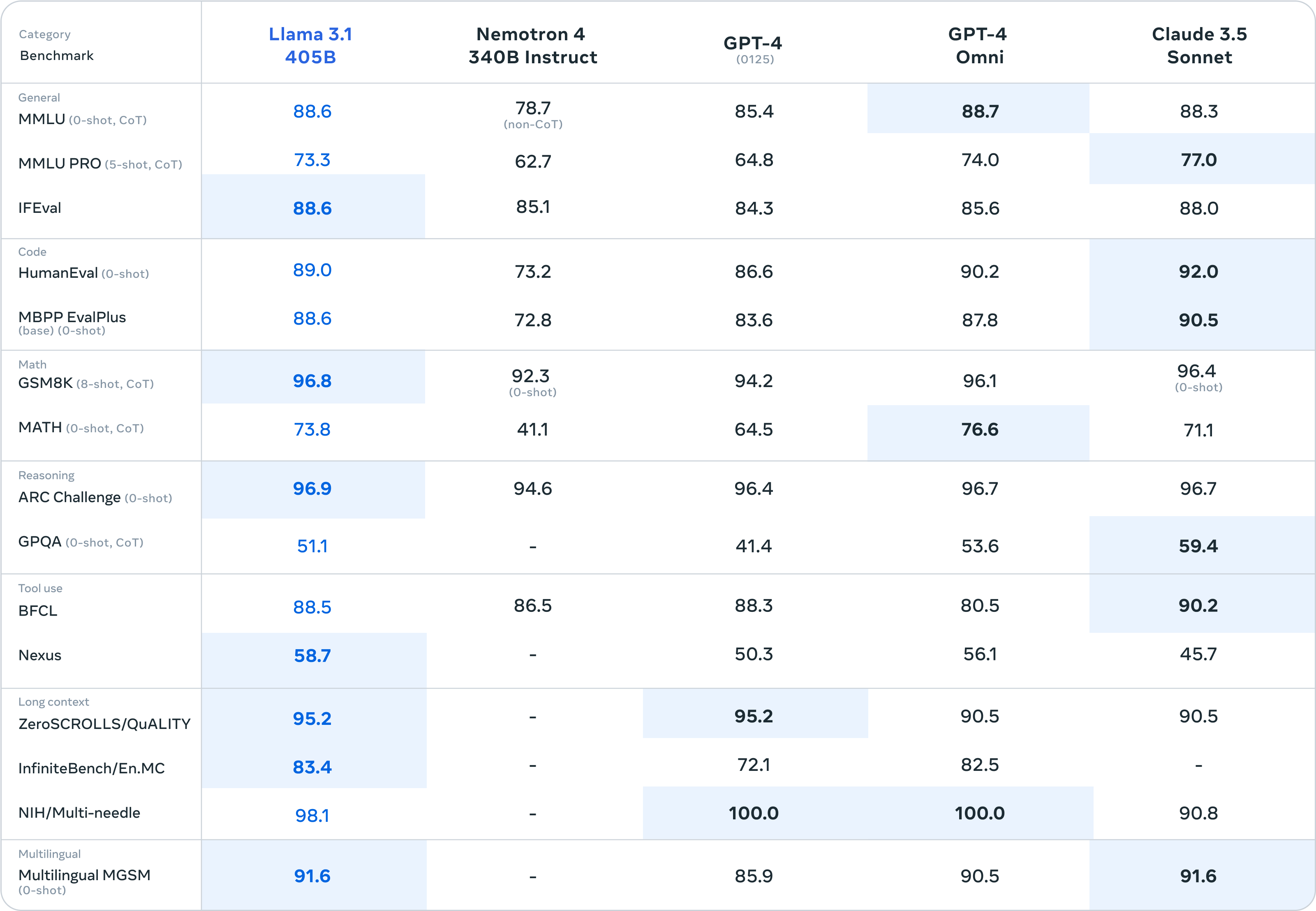
Llama 3.1, boasting 405 billion parameters, demonstrates competitive capabilities when compared to other leading models such as GPT-4 and Claude 3.5 Sonnet. The model's performance is particularly noteworthy in several key areas:
• General Language Understanding: Llama 3.1 achieves a score of 88.6 on the MMLU (Massive Multitask Language Understanding) test, placing it on par with GPT-4 Omni (88.7) and slightly ahead of Claude 3.5 Sonnet (88.3).
• Mathematical Reasoning: The model excels in mathematical tasks, scoring 96.8 on the GSMBK (Grade School Math Benchmarks) test, showcasing strong capabilities in basic mathematical operations and problem-solving.
• Reasoning and Logic: With a score of 96.9 on the ARC Challenge, Llama 3.1 demonstrates exceptional reasoning skills, matching the performance of top-tier models in this category.
• Multilingual Proficiency: The model's score of 91.6 on the Multilingual MGSM benchmark indicates robust capabilities in handling multiple languages, a crucial feature in our increasingly globalized world.
• Code Comprehension: Llama 3.1 shows strong performance in code-related tasks, with scores of 89.0 on HumanEval and 88.6 on MBPP EvalPlus, suggesting significant potential for programming and software development applications.
• Long-form Content Generation: The model's score of 95.2 on the ZeroSCROLLS/QuALITY test indicates proficiency in generating and understanding extended pieces of text.
These results position Llama 3.1 as a formidable contender in the field of large language models, potentially reshaping the competitive landscape and opening new possibilities for AI applications across various domains.

Understanding AI Language Model Benchmarks: A Deep Dive
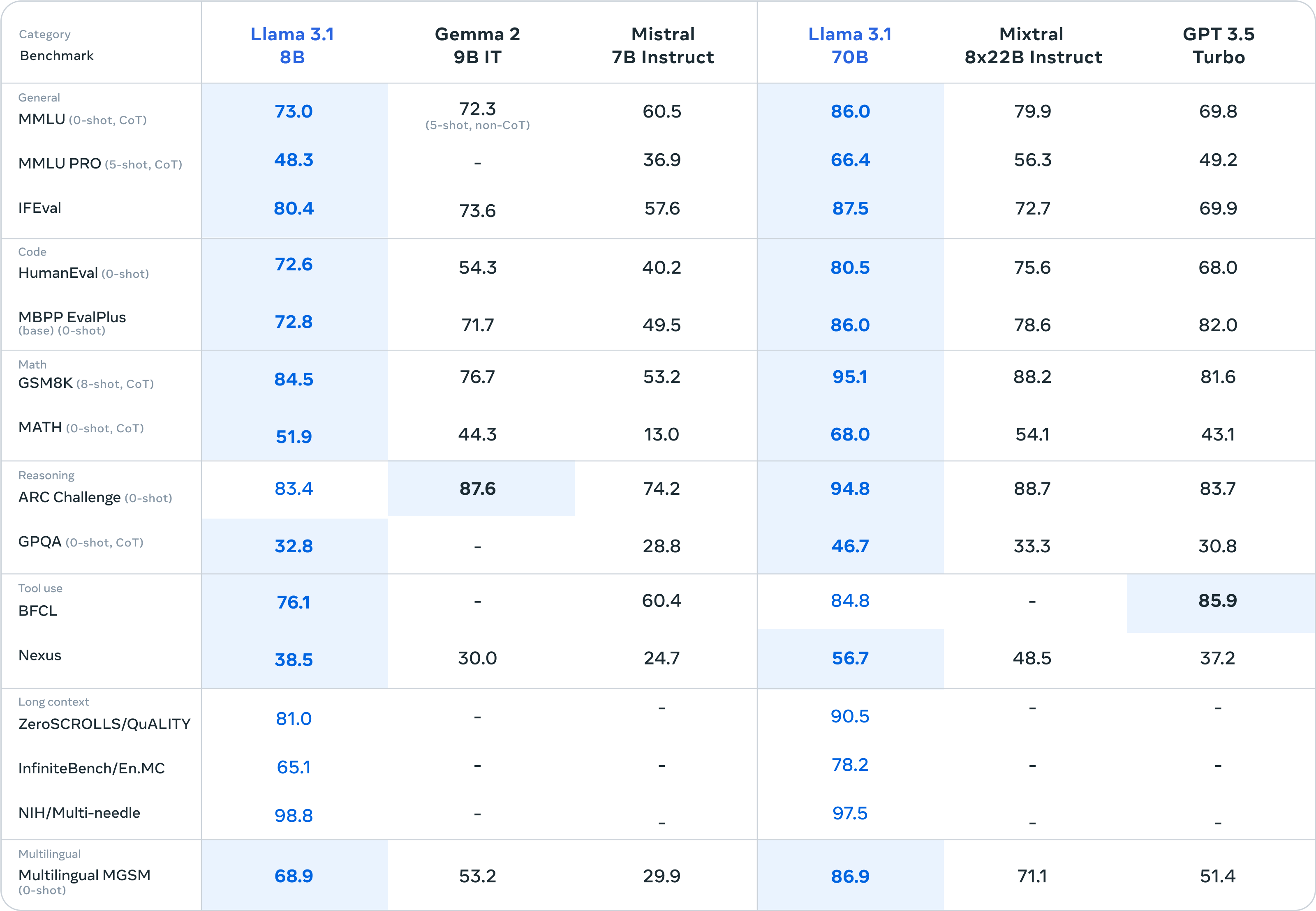
In the rapidly evolving world of artificial intelligence, language models have become increasingly sophisticated. To measure their capabilities, researchers use various benchmarks and tests. Let's break down the key parameters used to evaluate these AI powerhouses and understand what they mean for both tech enthusiasts and everyday users. Following tables showcase the comparison of Llama 3.1 405B and 8B models with other popular closed-source contenders.
(source: ollama.com)
General Language Understanding
MMLU (Massive Multitask Language Understanding):
This benchmark tests the model's ability to handle a wide range of tasks across various domains. The "(0-shot, CoT)" notation indicates that the model is evaluated without specific training examples (0-shot) and uses Chain-of-Thought reasoning.
In simple terms: Imagine asking someone questions about history, science, and literature without giving them time to study. MMLU is like that for AI – it tests how well the AI can answer questions on many topics without special preparation.
MMLU PRO:
This is likely an advanced version of MMLU, possibly with more complex or specialized questions.
In simple terms: Think of this as the "expert level" quiz for AI, testing its knowledge on more challenging or niche topics.
IFEval (Instruction Following Evaluation):
This benchmark assesses how well the model can follow specific instructions or prompts.
In simple terms: It's like giving the AI a set of directions and seeing how accurately it can follow them, similar to how well you might follow a recipe or assembly instructions.
Code Understanding
HumanEval:
This benchmark tests the model's ability to understand and generate code.
In simple terms: It's like asking the AI to read a computer program and then write some code to solve a problem or complete a task.
MBPP EvalPlus:
This likely stands for "Mostly Basic Python Programming EvalPlus," which evaluates the model's proficiency in Python programming tasks.
In simple terms: This test checks how well the AI can write and understand Python code, from basic to more advanced levels.
Math Skills
GSMBK (Grade School Math Benchmarks):
This benchmark tests the model's ability to solve grade school-level math problems.
In simple terms: It's like giving the AI a math test that a middle school student might take, covering basic arithmetic, algebra, and geometry.
MATH:
This likely refers to more advanced mathematical problem-solving.
In simple terms: Think of this as giving the AI a high school or college-level math exam, testing its ability to handle complex equations and mathematical concepts.
Reasoning
ARC Challenge (AI2 Reasoning Challenge):
This benchmark assesses the model's ability to answer questions that require reasoning skills.
In simple terms: Imagine giving the AI puzzles or logic problems that require thinking through multiple steps to arrive at the correct answer.
GPQA (Grounded Question Answering):
This test likely focuses on the model's ability to answer questions based on given information or context.
In simple terms: It's like asking the AI to read a passage and then answer questions about it, demonstrating that it understands the content and can draw conclusions.
Tool Use
BFCL (Benchmark for Function Calling):
This evaluates the model's ability to use or call specific functions or tools when needed.
In simple terms: Think of this as testing how well the AI can use different tools or abilities at its disposal to solve problems, like knowing when to use a calculator for complex math or a dictionary for definitions.
Nexus:
While not explicitly defined, this likely tests the model's ability to connect different pieces of information or use multiple tools in combination.
In simple terms: This might be like testing how well the AI can juggle multiple tasks or combine different skills to solve complex problems.
Long Content
ZeroSCROLLS/QuALITY:
This benchmark likely tests the model's ability to handle and generate long-form content.
In simple terms: It's like asking the AI to read a long article or book and then write an equally long and coherent piece on a similar topic.
InfiniteBench/En.MC:
This may be testing the model's ability to handle extremely long or complex texts, possibly in multiple choice format.
In simple terms: Imagine giving the AI a very long book to read and then asking it detailed questions about the content, with multiple choice answers.
NIH/Multi-needle:
This benchmark likely tests the model's ability to find specific information within large datasets, possibly related to medical or scientific literature.
In simple terms: It's like asking the AI to quickly find a specific piece of information in a huge library of medical journals.
Multilingual
Multilingual MGSM:
This benchmark tests the model's ability to understand and generate content in multiple languages.
In simple terms: It's like testing how well the AI can communicate in different languages, from understanding questions to providing answers across various linguistic contexts.
Comparing the Models
Now that we understand the benchmarks, let's look at how the different models perform:
Llama 3.1 (405B):
Llama 3.1 shows strong performance across most categories, particularly excelling in math skills (GSMBK), reasoning (ARC Challenge), and long-form content generation (ZeroSCROLLS/QuALITY). It also demonstrates impressive multilingual capabilities.
Nemoton 4 (340B Instruct):
While Nemoton 4 generally scores lower than its competitors, it still shows solid performance in general language understanding and reasoning tasks. It's worth noting that data for several benchmarks is missing for this model.
GPT-4 (Instruct and Omni versions):
Both versions of GPT-4 demonstrate high performance across the board. The Omni version tends to score slightly higher in most categories, particularly in general language understanding and code-related tasks. GPT-4 excels in the NIH/Multi-needle task, achieving a perfect score.
Claude 3.5 Sonnet:
Claude 3.5 Sonnet shows impressive results, often matching or exceeding the performance of other models. It particularly shines in code understanding (HumanEval), math skills (MBPP EvalPlus), and tool use (BFCL).
What This Means for AI Development and Usage
The comparison table reveals several key insights about the current state of AI language models:
1. Generalization vs. Specialization: While all models perform well across various tasks, some excel in specific areas. This suggests that different models might be better suited for particular applications.
2. Continuous Improvement: The high scores across many benchmarks indicate that AI language models are becoming increasingly capable and versatile.
3. Remaining Challenges: Despite impressive performance, there are still areas where improvements can be made, particularly in advanced mathematical reasoning and certain specialized tasks.
4. Practical Applications: The strong performance in areas like code understanding, math skills, and multilingual capabilities points to the potential for these models to assist in a wide range of professional and educational contexts.
5. Ethical Considerations: As these models become more powerful, it's crucial to consider the ethical implications of their use, particularly in sensitive areas like healthcare (as suggested by the NIH/Multi-needle benchmark) or in generating long-form content that could be mistaken for human-written text.
To conclude, the comparison of these AI language models showcases the remarkable progress in the field of artificial intelligence. From general language understanding to specialized tasks like code generation and mathematical problem-solving, these models demonstrate capabilities that were once thought to be uniquely human.
However, it's important to remember that these benchmarks, while comprehensive, don't capture the full complexity of human intelligence. They are specific tests designed to measure certain aspects of language understanding and problem-solving. Real-world applications of these AI models may present challenges not covered by these benchmarks.
As AI continues to evolve, we can expect even more impressive capabilities in the future. The key will be harnessing these abilities responsibly and ethically, ensuring that AI remains a tool that enhances human capabilities rather than replacing them entirely. Share your thoughts by leaving a comment.